Code
library(warbleR)
pg <- query_xc(qword = 'Phaethornis guy', download = FALSE)
The warbleR function query_xc() queries for avian vocalization recordings in the open-access online repository Xeno-Canto. It can return recordings metadata or download the associated sound files.
Get recording metadata for green hermits (Phaethornis guy):
library(warbleR)
pg <- query_xc(qword = 'Phaethornis guy', download = FALSE)
Keep only song vocalizations of high quality:
song_pg <- pg[grepl("song", ignore.case = TRUE, pg$Vocalization_type) & pg$Quality == "A", ]
# remove 1 site from Colombia to have a few samples per country
song_pg <- song_pg[song_pg$Locality != "Suaita, Santander", ]Map locations using map_xc():
map_xc(song_pg, leaflet.map = TRUE)
Once you feel fine with the subset of data you can go ahead and download the sound files and save the metadata as a .csv file:
query_xc(X = song_pg, path = "./examples/p_guy", parallel = 3)
write.csv(song_pg, file = "./examples/p_guy/metadata_p_guy_XC.csv", row.names = FALSE)
Now convert all to .wav format (mp3_2_wav) and homogenizing sampling rate and bit depth (fix_wavs):
mp3_2_wav(samp.rate = 22.05, path = "./examples/p_guy")
fix_wavs(path = "./examples/p_guy", samp.rate = 44.1, bit.depth = 16)
Now songs should be manually annotated and all the selection in the .txt files should be pooled together in a single spreadsheet.
Once that is done we can read the spreadsheet with the package ‘readxl’ as follows:
# install.packages("readxl") # install if needed
# load package
library(readxl)
# read data
annotations <- read_excel(path = "./examples/p_guy/annotations_p_guy.xlsx")
# check data
head(annotations)| selec | Channel | start | end | bottom.freq | top.freq | selec.file |
|---|---|---|---|---|---|---|
| 1 | 1 | 0.7737 | 0.9939384 | 2.0962 | 7.7252 | Phaethornis-guy-2022.Table.1.selections.txt |
| 2 | 1 | 1.6837 | 1.9068363 | 2.0726 | 7.6074 | Phaethornis-guy-2022.Table.1.selections.txt |
| 3 | 1 | 10.1657 | 10.3917342 | 1.8371 | 8.0078 | Phaethornis-guy-2022.Table.1.selections.txt |
| 4 | 1 | 16.3237 | 16.5468363 | 2.0726 | 7.3248 | Phaethornis-guy-2022.Table.1.selections.txt |
| 5 | 1 | 1.6069 | 1.7517937 | 1.7193 | 8.7615 | Phaethornis-guy-2022.Table.1.selections.txt |
| 6 | 1 | 1.0129 | 1.1548958 | 1.7193 | 8.9264 | Phaethornis-guy-2022.Table.1.selections.txt |
Note that the column names should be: “start”, “end”, “bottom.freq”, “top.freq” and “sound.files”. In addition frequency columns (“bottom.freq” and “top.freq”) must be in kHz, not in Hz. We can check if the annotations are in the right format using warbleR’s check_sels():
sound_file_path <- "./examples/p_guy/converted_sound_files/"
cs <- check_sels(annotations, path = sound_file_path)all selections are OK
We can measured several parameters of acoustic structure with the warbleR function spectro_analysis():
sp <- spectro_analysis(X = annotations, path = sound_file_path)
Then we summarize those parameters with a Principal Component Analysis (PCA):
# run excluding sound file and selec columns
pca <- prcomp(sp[, -c(1, 2)])
# add first 2 PCs to sound file and selec columns
pca_data <- cbind(sp[, c(1, 2)], pca$x[, 1:2])
At this point should should get someting like this:
head(pca_data)| sound.files | selec | PC1 | PC2 |
|---|---|---|---|
| Phaethornis-guy-227574.wav | 1 | 22.5940413 | 13.148139 |
| Phaethornis-guy-227574.wav | 2 | -0.1051713 | 17.152528 |
| Phaethornis-guy-227574.wav | 3 | -8.2102916 | -1.806982 |
| Phaethornis-guy-227574.wav | 4 | 6.9500021 | -4.559926 |
| Phaethornis-guy-238804.wav | 5 | -11.0761462 | -7.156525 |
| Phaethornis-guy-238804.wav | 6 | -4.5189993 | -8.129007 |
‘PC1’ and ‘PC2’ are the 2 new dimensions that will be used to represent the acoustic space.
Now we just need to add any metadata we considered important to try to explain acoustic similarities shown in the acoustic space scatterplot:
# read XC metadata
song_pg <- read.csv("./examples/p_guy/metadata_p_guy_XC.csv")
# create a column with the file name in the metadata
song_pg$sound.files <- paste0(song_pg$Genus, "-", song_pg$Specific_epithet, "-", song_pg$Recording_ID, ".wav")
# and merge based on sound files and any metadata column we need
pca_data_md <- merge(pca_data, song_pg[, c("sound.files", "Country", "Latitude", "Longitude")])
We are ready to plot the acoustic space scatterplot. For this we will use the package ‘ggplot2’:
# install.packages("ggplot2")
library(ggplot2)
# install.packages("viridis")
library(viridis)Loading required package: viridisLite# plot
ggplot(data = pca_data_md, aes(x = PC1, y = PC2, color = Country, shape = Country)) +
geom_point(size = 3) +
scale_color_viridis_d()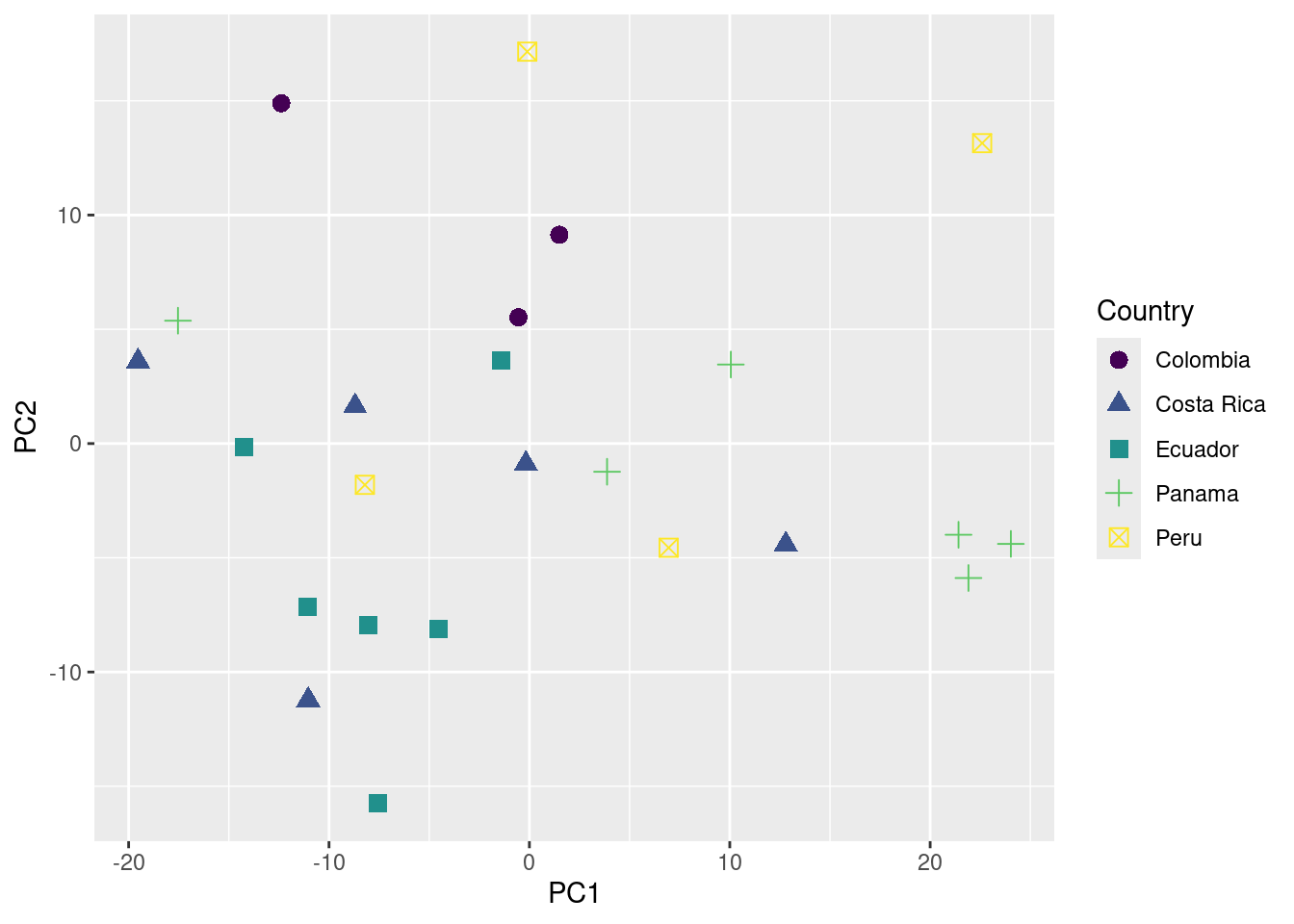
You can also add information about their geographic location (in this case longitude) to the plot as follows:
# plot
ggplot(data = pca_data_md, aes(x = PC1, y = PC2, color = Longitude, shape = Country)) +
geom_point(size = 3) +
scale_color_viridis_c()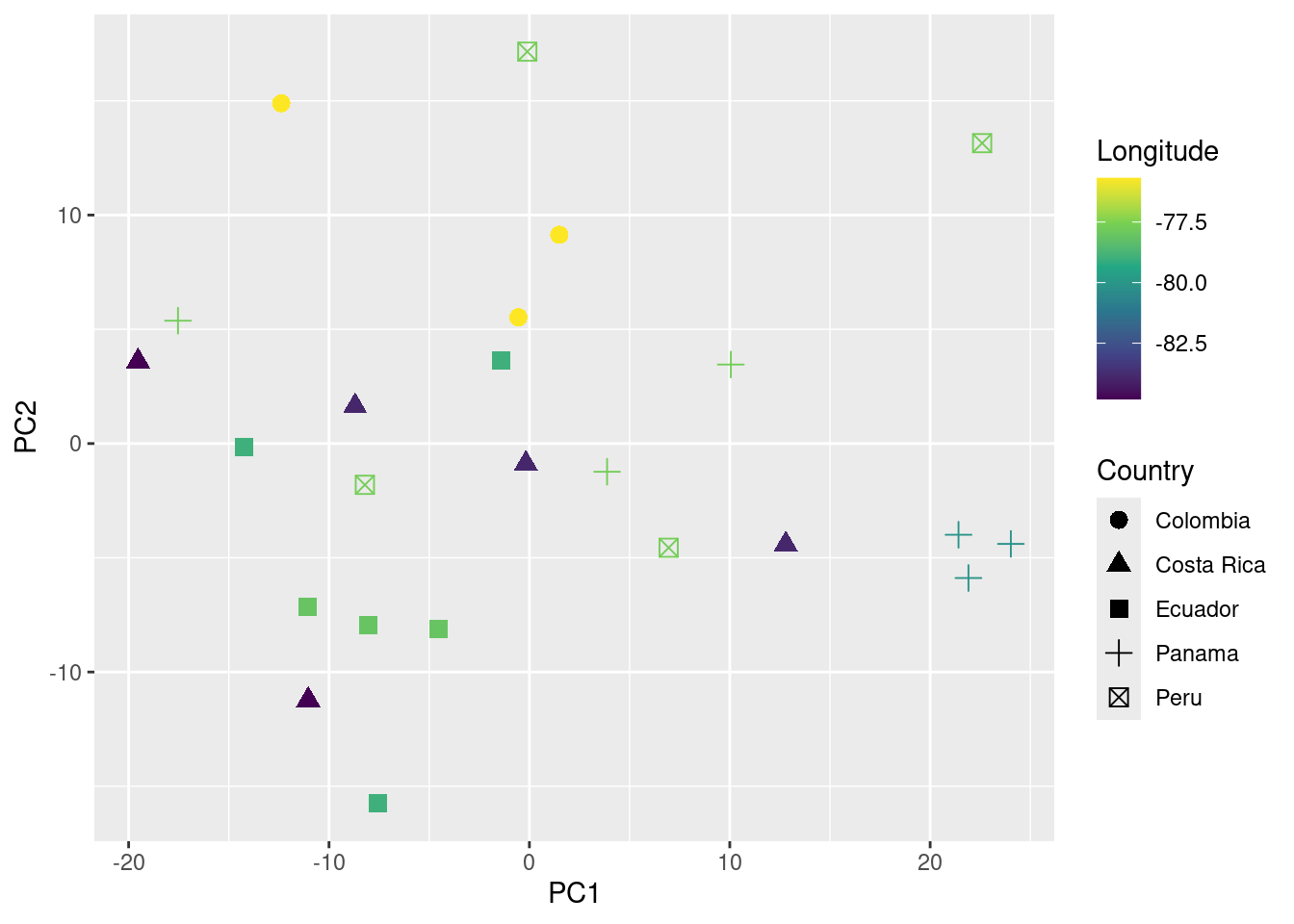
We can even test if geographic distance is associated to acoustic distance (i.e. if individuals geographically closer produce more similar songs) using a mantel test (mantel function from the package vegan):
# create geographic and acoustic distance matrices
geo_dist <- dist(pca_data_md[, c("Latitude", "Longitude")])
acoust_dist <- dist(pca_data_md[, c("PC1", "PC2")])
# install.packages("vegan")
library(vegan)
# run test
mantel(geo_dist, acoust_dist)
Mantel statistic based on Pearson's product-moment correlation
Call:
mantel(xdis = geo_dist, ydis = acoust_dist)
Mantel statistic r: 0.02618
Significance: 0.267
Upper quantiles of permutations (null model):
90% 95% 97.5% 99%
0.0774 0.1072 0.1395 0.1795
Permutation: free
Number of permutations: 999
In this example no association between geographic and acoustic distance was detected (p value > 0.05).
Session information
R version 4.3.2 (2023-10-31)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 22.04.2 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/Costa_Rica
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] vegan_2.6-4 lattice_0.20-45 permute_0.9-7 viridis_0.6.5
[5] viridisLite_0.4.2 ggplot2_3.5.1 readxl_1.4.3 warbleR_1.1.30
[9] NatureSounds_1.0.4 knitr_1.46 seewave_2.2.3 tuneR_1.4.6
loaded via a namespace (and not attached):
[1] gtable_0.3.4 rjson_0.2.21 xfun_0.43 htmlwidgets_1.6.4
[5] vctrs_0.6.5 tools_4.3.2 crosstalk_1.2.1 bitops_1.0-7
[9] generics_0.1.3 parallel_4.3.2 tibble_3.2.1 proxy_0.4-27
[13] fansi_1.0.6 cluster_2.1.2 pkgconfig_2.0.3 Matrix_1.6-5
[17] leaflet_2.2.1 lifecycle_1.0.4 compiler_4.3.2 farver_2.1.1
[21] brio_1.1.4 munsell_0.5.0 codetools_0.2-18 htmltools_0.5.8.1
[25] maps_3.4.2 RCurl_1.98-1.14 yaml_2.3.8 pillar_1.9.0
[29] jquerylib_0.1.4 MASS_7.3-55 iterators_1.0.14 foreach_1.5.2
[33] nlme_3.1-155 tidyselect_1.2.0 digest_0.6.35 dplyr_1.1.4
[37] labeling_0.4.3 splines_4.3.2 fastmap_1.1.1 grid_4.3.2
[41] colorspace_2.1-0 cli_3.6.2 magrittr_2.0.3 utf8_1.2.4
[45] withr_3.0.0 scales_1.3.0 shinyBS_0.61.1 rmarkdown_2.26
[49] signal_1.8-0 gridExtra_2.3 cellranger_1.1.0 pbapply_1.7-2
[53] evaluate_0.23 dtw_1.23-1 fftw_1.0-8 testthat_3.2.1
[57] mgcv_1.8-39 rlang_1.1.3 Rcpp_1.0.12 glue_1.7.0
[61] rstudioapi_0.15.0 jsonlite_1.8.8 R6_2.5.1 soundgen_2.6.2